To quick start, you can run DeepSeek-LLM-7B-Chat with just one single command on your own device. The command tool automatically downloads and installs the WasmEdge runtime, the model files, and the portable Wasm apps for inference.
DeepSeek-LLM-7B-Chat is an advanced language model trained by DeepSeek, a subsidiary company of High-flyer quant, comprising 7 billion parameters. It is trained on a dataset of 2 trillion tokens in English and Chinese. The DeepSeek LLM 7B/67B Base and DeepSeek LLM 7B/67B Chat versions have been made open source, aiming to support research efforts in the field.
In this article, we will cover
- How to run DeepSeek-LLM-7B-Chat on your own device
- How to create an OpenAI-compatible API service for DeepSeek-LLM-7B-Chat
We will use the Rust + Wasm stack to develop and deploy applications for this model. There are no complex Python packages or C++ toolchains to install! See why we choose this tech stack.

Run the DeepSeek-LLM-7B-Chat model on your own device
Step 1: Install WasmEdge via the following command line.
curl -sSf https://raw.githubusercontent.com/WasmEdge/WasmEdge/master/utils/install.sh | bash -s -- --plugins wasmedge_rustls wasi_nn-ggml
Step 2: Download the DeepSeek-LLM-7B-Chat model GGUF file. It may take a long time, since the size of the model is several GBs.
curl -LO https://huggingface.co/second-state/Deepseek-LLM-7B-Chat-GGUF/resolve/main/deepseek-llm-7b-chat.Q5_K_M.gguf
Step 3: Download a cross-platform portable Wasm file for the chat app. The application allows you to chat with the model on the command line. The Rust source code for the app is here.
curl -LO https://github.com/LlamaEdge/LlamaEdge/releases/latest/download/llama-chat.wasm
That's it. You can chat with the model in the terminal by entering the following command.
wasmedge --dir .:. --nn-preload default:GGML:AUTO:deepseek-llm-7b-chat.Q5_K_M.gguf llama-chat.wasm -p deepseek-chat
The portable Wasm app automatically takes advantage of the hardware accelerators (eg GPUs) I have on the device.
On my Mac M2 16G memory device, it clocks in at about 14 tokens per second.
[You]: How can I download a Youtube video to my local device?
There are several ways to download a YouTube video to your local device, including using a browser extension, a dedicated YouTube downloader app, or a third-party software. Here are some steps to download a YouTube video using a browser extension:
1. Download and install a browser extension that allows you to download YouTube videos, such as Video DownloadHelper or SaveFrom.net.
2. Open the YouTube video you want to download in your web browser.
3. Install the browser extension and enable it.
4. Right-click on the video and select "Save Video As" or "Download" from the context menu.
5. Choose a location on your local device to save the video and select a format.
6. Wait for the download to complete.
Note that downloading YouTube videos may violate the site's terms of service, and some videos may be protected by copyright. Always make sure you have the necessary permissions and rights to download and use a video before doing so.
Create an OpenAI-compatible API service for the DeepSeek-LLM-7B-Chat model
An OpenAI-compatible web API allows the model to work with a large ecosystem of LLM tools and agent frameworks such as flows.network, LangChain and LlamaIndex.
Download an API server app. It is also a cross-platform portable Wasm app that can run on many CPU and GPU devices.
curl -LO https://github.com/LlamaEdge/LlamaEdge/releases/latest/download/llama-api-server.wasm
Then, download the chatbot web UI to interact with the model with a chatbot UI.
curl -LO https://github.com/LlamaEdge/chatbot-ui/releases/latest/download/chatbot-ui.tar.gz
tar xzf chatbot-ui.tar.gz
rm chatbot-ui.tar.gz
Next, use the following command lines to start an API server for the model. Then, open your browser to http://localhost:8080 to start the chat!
wasmedge --dir .:. --nn-preload default:GGML:AUTO:deepseek-llm-7b-chat.Q5_K_M.gguf llama-api-server.wasm -p deepseek-chat
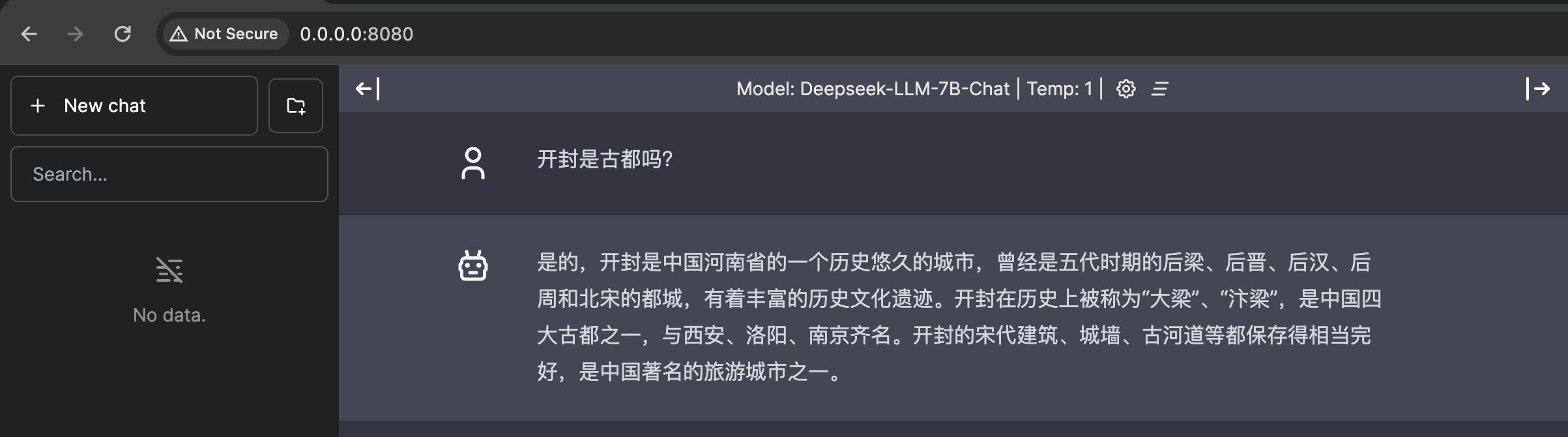 (The model excels in Chinese, so we ask another Chinese question to test the model.)
(The model excels in Chinese, so we ask another Chinese question to test the model.)
You can also interact with the API server using curl from another terminal .
curl -X POST http://localhost:8080/v1/chat/completions \
-H 'accept:application/json' \
-H 'Content-Type: application/json' \
-d '{"messages":[{"role":"system", "content": "You are a helpful assistant."}, {"role":"user", "content": "What's the capital of Paris"}], "model":"Deepseek-LLM-7B"}'
That’s all. WasmEdge is easiest, fastest, and safest way to run LLM applications. Give it a try!
Join the WasmEdge discord to ask questions and share insights. Any questions getting this model running? Please go to second-state/LlamaEdge to raise an issue or book a demo with us to enjoy your own LLMs across devices!