AI inference on the edge
Fast, lightweight,
portable, rust-powered and OpenAI compatible
Powered by WasmEdge.

















Zero python dependency! Take full advantage of the GPUs. Write once, run anywhere. Get started with
Llama 2 series of models on your own device in 5 minutes.
Rust

Retrieval-argumented fmgeneration (RAG) is a very popular approach to build AI agents with external
knowledge bases. Create your own in flows.network.
Rust | Example: Learn Rust
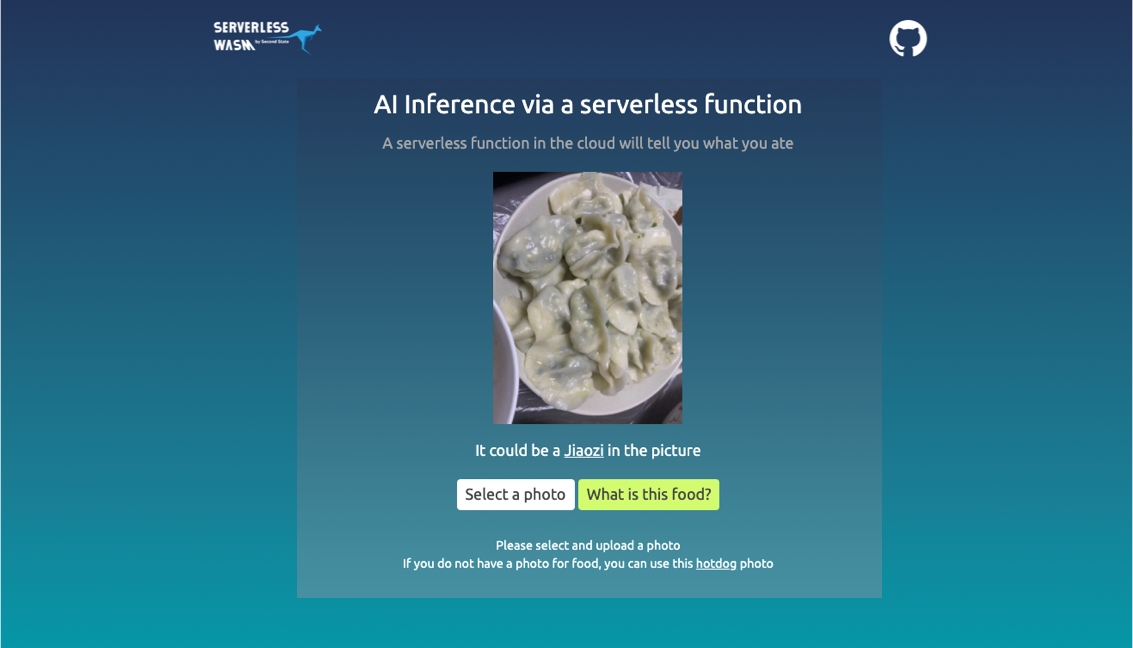
Create an HTTP microservice for image classification. It runs YOLO and Mediapipe models at native GPU speed.
A cloud-native and edge-native WebAssembly Runtime
A WebAssembly runtime for dapr microservices.
A node.js compatible JavaScript runtime for WasmEdge
Building Rust functions with WebAssembly
The easiest & fastest way to run customized and fine-tuned LLMs locally or on the edge.