
Besides the launch of CodeLlama-70B recently, there's been another attention catcher in the open-source Large Language Models (LLM) field. You must have also caught it. It's the suspected leak of Mistral AI's crown-jewel large language model, Mistral Medium, on Hugging Face.
Mistral AI, a Paris-based AI startup, has released three widely recognized models: Mistral-7b-Instruct-v0.1, Mistral-7b-Instruct-V0.2, and the first open source MoE architecture model, Mixtral 8x7B, which showed outstanding performance and can be considered the best-performing open-source model on the market.
In December 2023, Mistral AI launched its API service platform. In its introductory article, Mistral AI mentioned that it would offer three model API services. Mistral-tiny is based on the existing Mistral 7B Instruct v0.2, and Mistral-small is based on the existing Mixtral 8x7B MoE model. The third one, the non-open-source secret weapon, Mistral medium, was introduced as based on a prototype model under testing but with higher performance.
According to the above benchmarks circulating on the internet, the performance of the mistral-medium API rivals gpt-4-1106-preview, raising expectations for Mistral Medium.
[Arena] Exciting update! Mistral Medium has gathered 6000+ votes and is showing remarkable performance, reaching the level of Claude. Congrats @MistralAI!
— lmsys.org (@lmsysorg) January 10, 2024
We have also revamped our leaderboard with more Arena stats (votes, CI). Let us know any thoughts :)
Leaderboard… pic.twitter.com/XbY3dN9zMz
6 days ago, a user named miqudev released the miqu-1-70b models on Hugging Face. miqudev didn't leave much information on Hugging Face, only mentioning that the prompt template is mistral. The performance of miqu-1-70b has sparked speculation among open-source large model enthusiasts about the model's origin. According to naming convention, “mi” might represent mistral, and “qu” might represent quantification, suggesting that miqu-1-70b is Mistral's quantified 70 B model. Could this be the leaked Mistral Medium?
I have some numbers on mystery miqu-70B. The model scores highly on MT-bench right after mistral medium. Is this a legit model leak? 61%~ humaneval pic.twitter.com/eZuN5T4arh
— anton (@abacaj) January 31, 2024
This morning, Arthur Mensch, CEO of Mistral AI, stated on Twitter that an employee of a client with early access leaked an old model trained by Mistral AI. Mistral AI has since completed retraining of the model.
An over-enthusiastic employee of one of our early access customers leaked a quantised (and watermarked) version of an old model we trained and distributed quite openly.
— Arthur Mensch (@arthurmensch) January 31, 2024
To quickly start working with a few selected customers, we retrained this model from Llama 2 the minute we got…
Arthur Mensch's tweet is considered by many to subtly confirm that miqu-1-70b is the leaked Mistral Medium model. So now, let's run miqu-1-70b locally and see how it performs.
How to run the legendary Mistral Medium: miqu-1-70b
We still use LlamaEdge to run the miqu-1-70b model. A significant reason is that LlamaEdge's composability design enables it to easily support the market's new large models.
In LlamaEdge, not only is the inference Wasm application itself cross-platform portable, but the inference application and prompt template can also be freely combined. If there's a new model using a prompt template that LlamaEdge has supported, you only need to download the model GGUF file to run this new model without needing to write a new inference program and compile it.
miqu-1-70b is such a case because it still uses mistral as the prompt template. If you've already downloaded WasmEdge and the inference application llama-chat.wasm or llama-api-server.wasm, you just need to download the miqu-1-70b model and run the following command line.
wasmedge --dir .:. --nn-preload default:GGML:AUTO:miqu-1-70b.q2_K.gguf llama-chat.wasm -p mistral-instruct
If you haven't downloaded WasmEdge and the corresponding inference Wasm files before, or are not familiar with LlamaEdge, you can use this command line tool to automate this part of the work.
bash <(curl -sSfL 'https://code.flows.network/webhook/iwYN1SdN3AmPgR5ao5Gt/run-llm.sh')
First, it will install the WasmEdge runtime. In the second step, when selecting the model, paste the following link into the command line.
https://huggingface.co/miqudev/miqu-1-70b
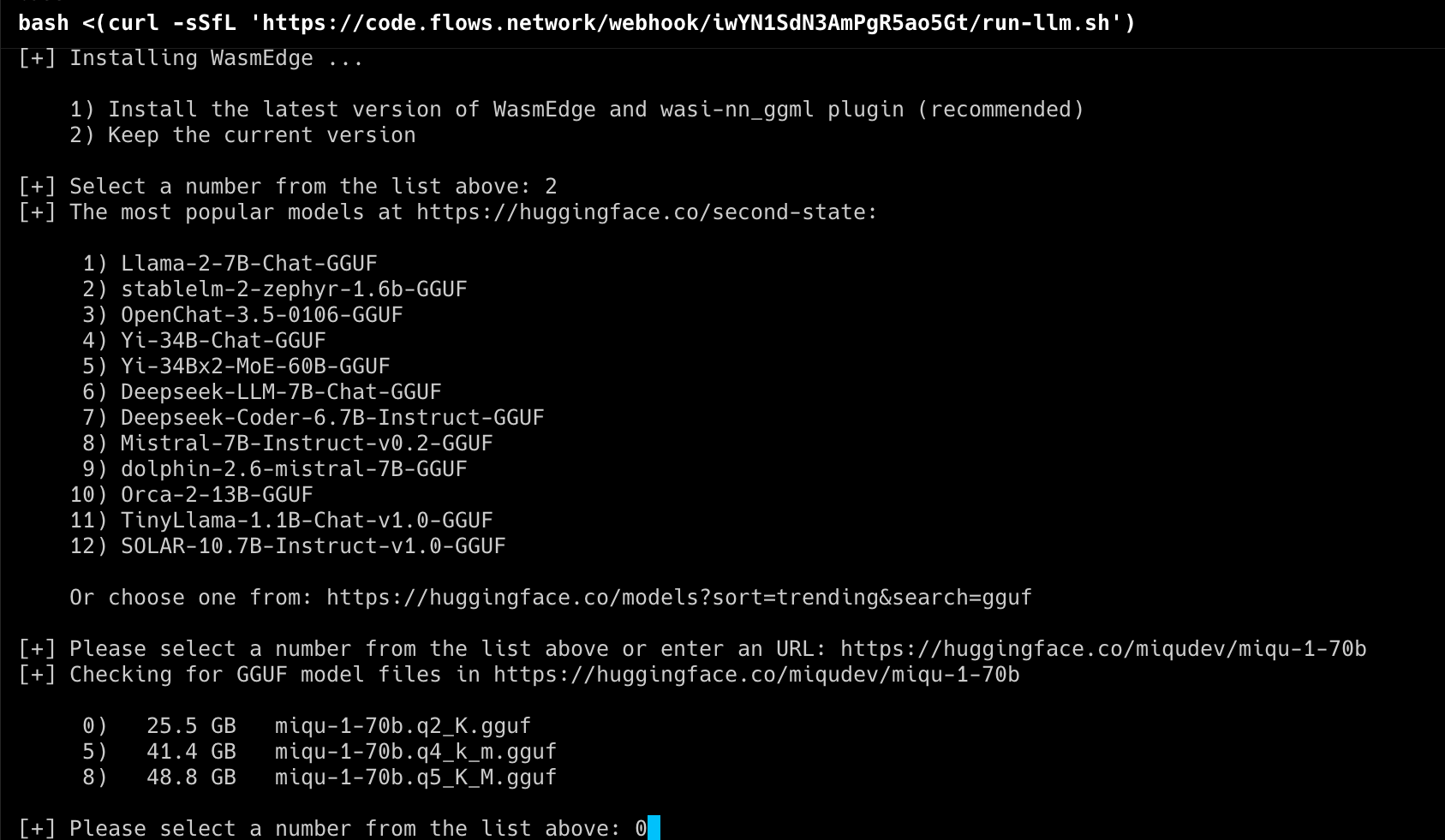
Then, based on the actual disk size and memory of your machine, choose one suitable quantization version sizes.
After the model is downloaded, the next step is to select the mistral-instruct prompt template as prompt template. The number is 5. Follow the command line tool's prompts, download the Wasm inference files, run the model, and that's it.
The performance of the miqu-1-70b model
How does the miqu-1-70b model perform? Let's test it with a very puzzling reasoning question. Reasoning ability is very important for building LLM agents.
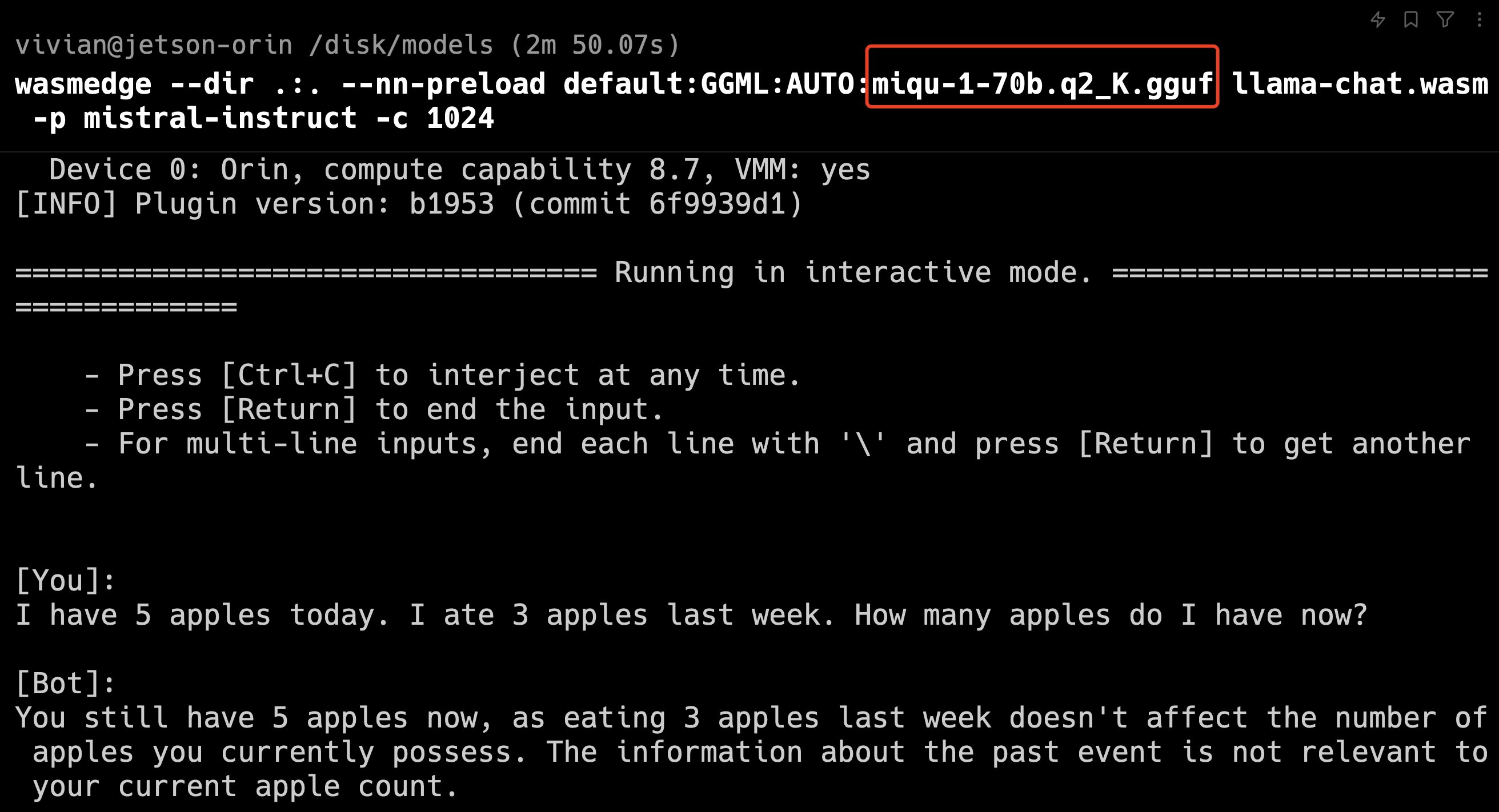
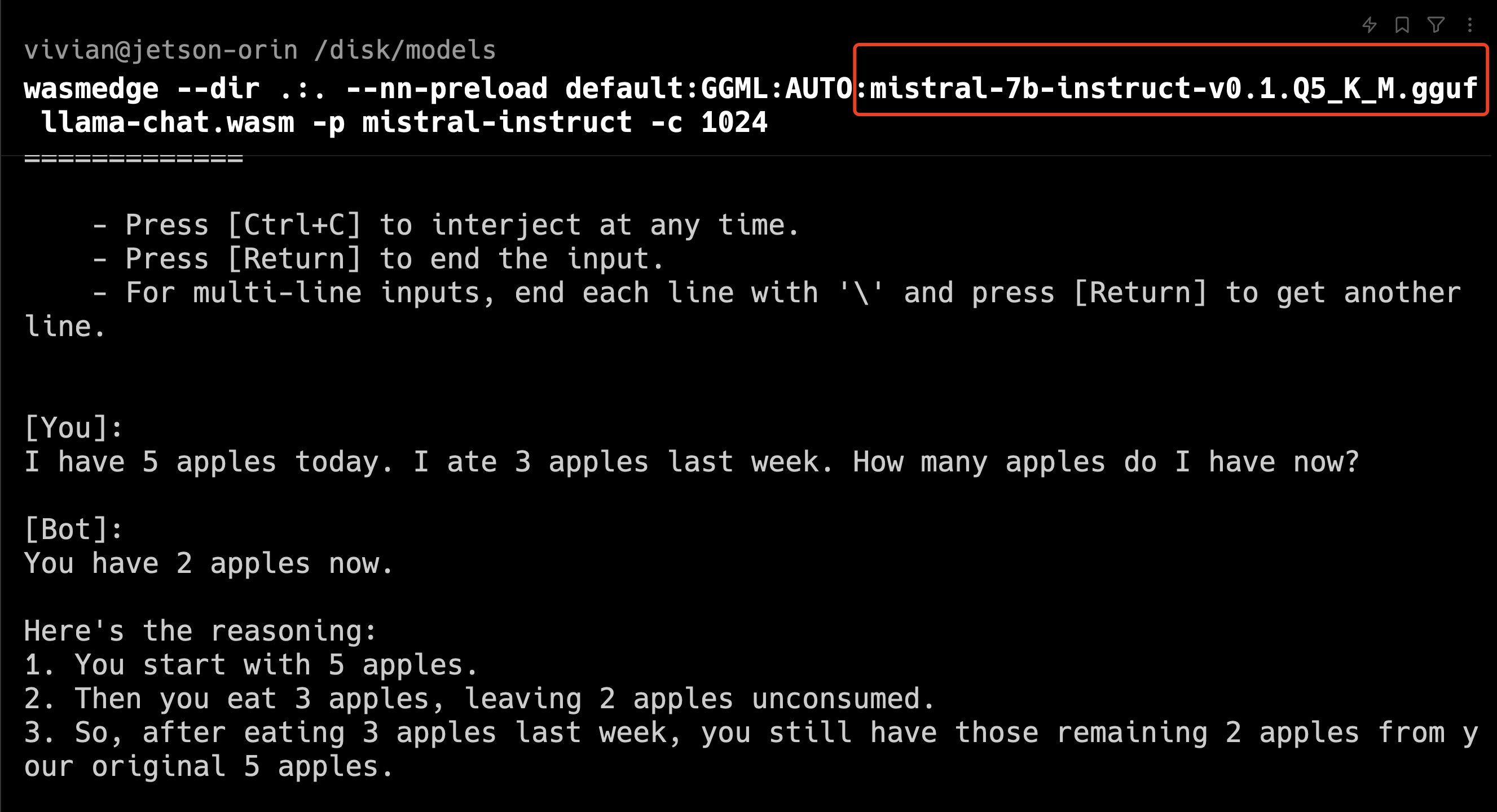
“I have 5 apples today. I ate 3 apples last week. How many apples do I have now?”
This is the answer from miqu-1-70b, aka mistral medium, which performed well and was not confused by the question. Moreover, I used a a lower-precision q2 version here.
However, its sibling, mistral-7b-instruct, gave a wrong answer.
We have the leaked “Mistral Medium” LLM running on our office Jetson using LlamaEdge. It is a 70B LLM with strong reasoning capabilities.
— wasmedge (@realwasmedge) February 1, 2024
Left is the 70B answering a tricky logic question. Right is Mistral 7B answering the same.
Reasoning is crucial for RAG and agent apps! https://t.co/pj4x8uOv16 pic.twitter.com/YfamGcqgYK
We have also tested this question with several open source models before, and among the many models, only Mixtral 8x7b answered correctly. Now we can say miqu-1-70b has quite good performance.
If you are also interested, welcome to run the open source LLMs with https://github.com/LlamaEdge/LlamaEdge/!