OpenAI just got a lot more open. OpenAI announced two state-of-the-art open-weight language models: gpt-oss-120b and gpt-oss-20b. Both models provide full chain-of-thought (CoT) and support Structured outputs, tool use, and function calling.
According to OpenAI, The gpt-oss-120b model matches the core reasoning performance of OpenAI’s o4-mini while running efficiently on a single 80 GB GPU. Meanwhile, the gpt-oss-20b model delivers results comparable to OpenAI’s o3-mini on standard benchmarks and can run on edge devices with just 16 GB of memory—making it well-suited for on-device applications, local inference, and fast iteration without the need for expensive infrastructure.

In this guide, we’ll show you how to run gpt-oss on your own machine using a Rust + Wasm stack — no need for heavy Python dependencies or complex C++ toolchains! See why we choose this tech stack.
Run OpenAI’s gpt-oss on your machine
Step 1: Install WasmEdge
Use the following command to install the latest version of WasmEdge:
curl -sSf https://raw.githubusercontent.com/WasmEdge/WasmEdge/master/utils/install_v2.sh | bash -s -- -v 0.14.1
Step 2: Download the quantized gpt-oss-20b model
The model is 12.1 GB in size and it will take minutes to download the model.
curl -LO https://huggingface.co/ggml-org/gpt-oss-20b-GGUF/resolve/main/gpt-oss-20b-mxfp4.gguf
Step 3: Download the LlamaEdge API server
It is a cross-platform portable Wasm app that can run on many CPU and GPU devices. The version of your LlamaEdge API server for running gpt-oss with tool calls support should be 0.25.1 or above.
curl -LO https://github.com/LlamaEdge/LlamaEdge/releases/latest/download/llama-api-server.wasm
Step 4: Start the gpt-oss API Server
Next, use the following command lines to start a LlamaEdge API server for the gpt-oss-20b. LlamaEdge provides an OpenAI compatible API, and you can connect any chatbot client or agent to it!
wasmedge --dir .:. --nn-preload default:GGML:AUTO:gpt-oss-20b-mxfp4.gguf \
llama-api-server.wasm \
--model-name gpt-oss-20b \
--prompt-template `gpt-oss` \
--ctx-size 4096
Chat
We’ve released a new chatbot UI called Oji. It works as a web app, macOS app, or Windows app — and it connects to any OpenAI-compatible API.
To run the web version, use:
curl -LO https://github.com/apepkuss/Oji-Assistant/releases/download/v0.0.2/oji-web-v0.0.2.zip
unzip oji-web-v0.0.2.zip -d oji-web
cd oji-web
python3 -m http.server 10086
Download the mac version | Download the windows version | Download the Linux version
Now open http://localhost:10086 in your browser, click Settings, and set the AI Service Base URL to your LlamaEdge API. If you’re using LlamaEdge default setting, it should be http://localhost:8080/v1.
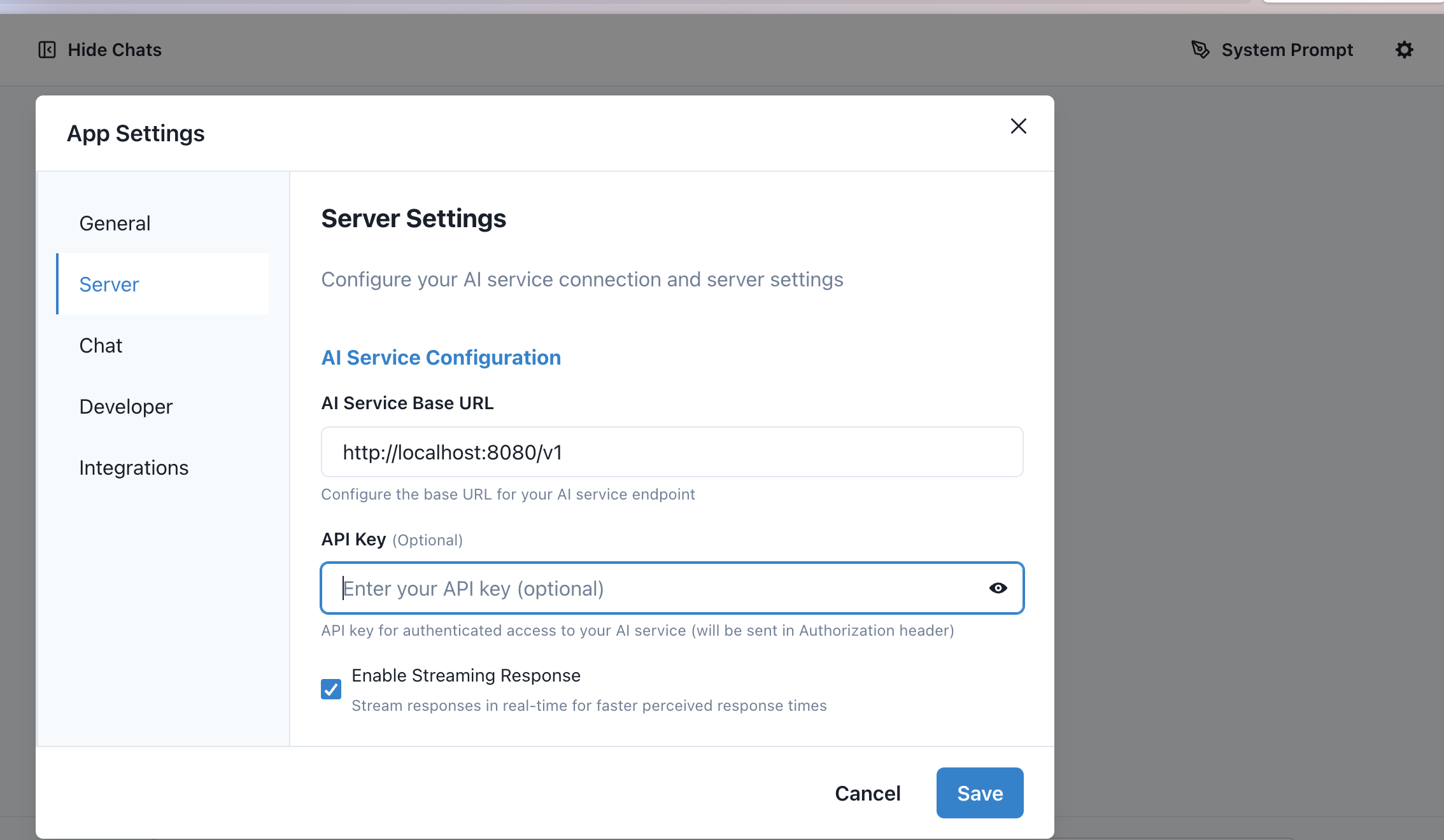
Once connected, you can start chatting with gpt-oss!
Use the OpenAI-Compatible API
The LlamaEdge API server is fully compatible with OpenAI API specs. You can send an API request to the model. Here's an example using curl:
curl -X POST http://localhost:8080/v1/chat/completions \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "gpt-oss-20b",
"messages": [
{"role": "system", "content": "You are a helpful assistant. Keep your answers concise."},
{"role": "user", "content": "Can a person be at the North Pole and the South Pole at the same time?"}
]
}'
The response will look something like this:
{
"id": "chatcmpl-xxx",
"model": "gpt-oss-20b",
"choices": [{
"message": {
"role": "assistant",
"content": "No, a person cannot be at both the North Pole and the South Pole at the same time. These are two distinct points on opposite ends of the Earth."
}
}]
}
RAG and Embeddings
Finally, if you are using gpt-oss to create agentic or RAG applications, you will likely need an API to compute vector embeddings for the user request text. That can be done by adding an embedding model to the LlamaEdge API server. Learn how this is done.
For agentic search, check out this tutorial.
MCP
If you’re building MCP-based agents, you can use gpt-oss as your LLM host together with Llama-Nexus as the MCP client. Get started quickly with our quick start guide.
Gaia
Alternatively, the Gaia network software allows you to stand up the gpt-oss, embedding model, and a vector knowledge base in a single command.
Join the WasmEdge discord to share insights. Any questions about getting this model running? Please go to second-state/LlamaEdge to raise an issue or book a demo with us to enjoy your own LLMs across devices!