Get ready for Qwen3! This is Alibaba's latest and most advanced large language model series! These models range in scale from 0.6 billion to 235 billion parameters, and are designed to excel in a wide range of tasks. Qwen3 is the world's first open-source hybrid reasoning model – integrating both ‘reasoning’ and ‘non-reasoning’ modes within the same model, allowing it to choose between ‘fast thinking’ and ‘slow thinking’ like humans, depending on the question.
According to official evaluations, Qwen3's flagship model, the MoE (Mixture-of-Experts) model Qwen3-235B-A22B, with 235 billion total parameters and 22 billion activated parameters, has achieved significant improvements in reasoning capabilities, surpassing Deepseek-R1 in mathematics, programming, and logical thinking. It also excels in understanding human preferences, making conversations more natural and engaging.
Qwen3-30B-A3B activates only 3 billion parameters during use, less than one-tenth of the previous Qwen series’ pure reasoning dense model, QwQ-32B, but with superior performance. Smaller parameter size and better performance mean developers can achieve better results with lower deployment and usage costs.
 In this article, we will cover how to run and interact withQwen-3on your own edge device on your own edge device.
In this article, we will cover how to run and interact withQwen-3on your own edge device on your own edge device.
We will use the Rust + Wasm stack to develop and deploy applications for this model. There are no complex Python packages or C++ toolchains to install! See why we choose this tech stack.
Run Qwen-3-4B
Step 1: Install WasmEdge via the following command line.
curl -sSf https://raw.githubusercontent.com/WasmEdge/WasmEdge/master/utils/install_v2.sh | bash -s -- -v 0.14.1
Step 2: Download the Quantized Qwen-3-4B Model
The model is 2.89 GB in size and it will take serveral minutes to download the model. If you want to run a different model, you will need to change the model download link below. Check out all the available Qwen 3 models from Second State’s Hugging Face page.
curl -LO https://huggingface.co/second-state/Qwen3-4B-GGUF/resolve/main/Qwen3-4B-Q5_K_M.gguf
Step 3: Download the LlamaEdge API server
It is a cross-platform portable Wasm app that can run on many CPU and GPU devices.
curl -LO https://github.com/LlamaEdge/LlamaEdge/releases/latest/download/llama-api-server.wasm
Step 4: Download the Chatbot UI to interact with the Qwen-3 model in the browser.
curl -LO https://github.com/LlamaEdge/chatbot-ui/releases/latest/download/chatbot-ui.tar.gz
tar xzf chatbot-ui.tar.gz
rm chatbot-ui.tar.gz
Next, use the following command lines to start a LlamaEdge API server for the model. LlamaEdge provides an OpenAI compatible API, and you can connect any chatbot client or agent to it! Copy
wasmedge --dir .:. --nn-preload default:GGML:AUTO:Qwen3-4B-Q5_K_M.gguf \
llama-api-server.wasm \
--model-name Qwen3-4B \
--prompt-template chatml \
--ctx-size 4096
Chat
Visit http://localhost:8080/ in your browser to interact with Qwen-3!
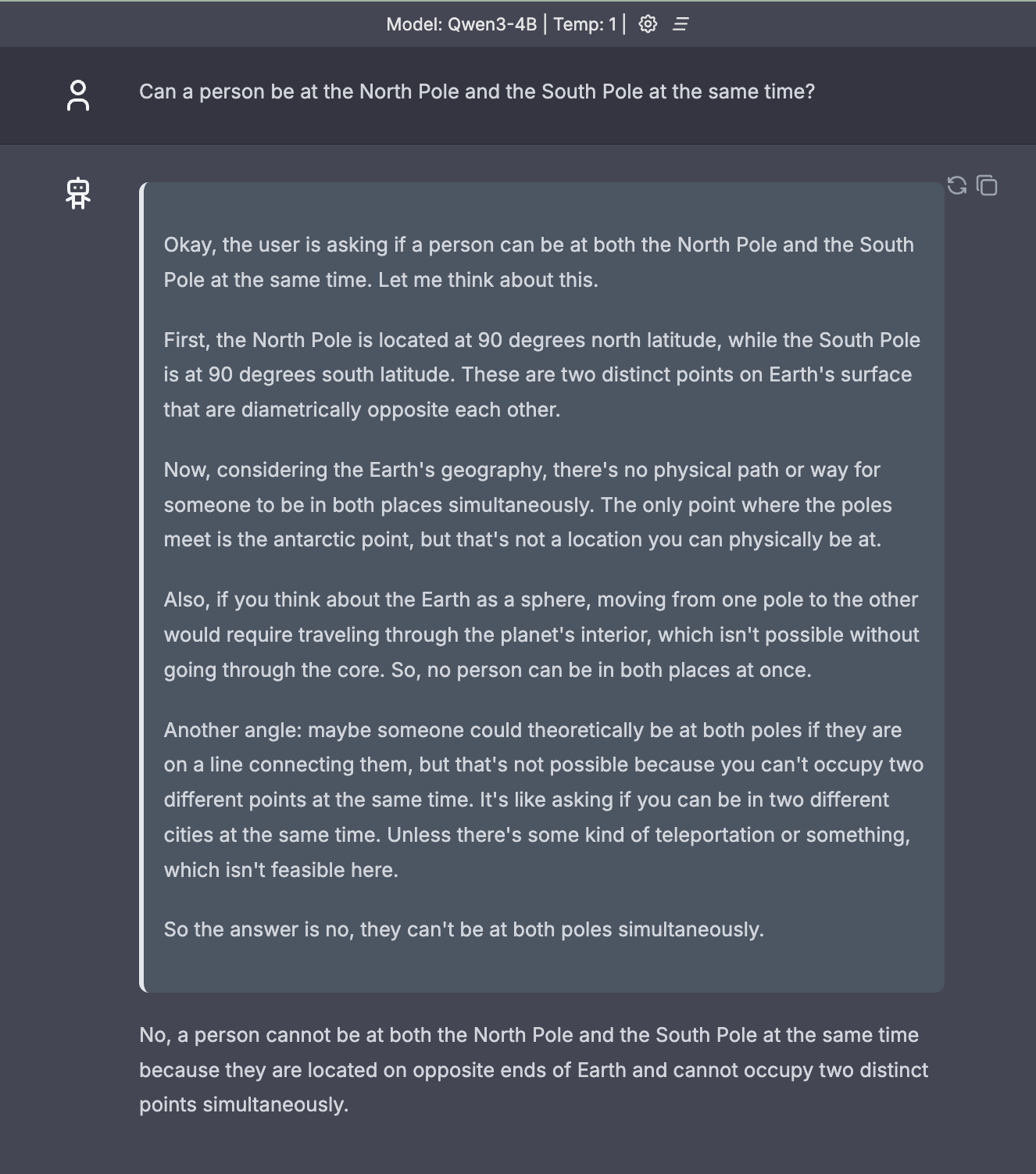
Use the API
The LlamaEdge API server is fully compatible with OpenAI API specs. You can send an API request to the model.
curl -X POST http://localhost:8080/v1/chat/completions \
-H 'accept:application/json' \
-H 'Content-Type: application/json' \
-d '{"messages":[{"role":"system", "content": "You are a helpful assistant. Answer as concise as possible"}, {"role":"user", "content": "Can a person be at the North Pole and the South Pole at the same time??"}], "model": "Qwen3-4B"}'
{"id":"chatcmpl-78fd1a57-c16c-4f87-8f8c-56ddc77b16d4","object":"chat.completion","created":1745906655,"model":"Qwen3-4B","choices":[{"index":0,"message":{"content":"<think>\nOkay, the user is asking if a person can be at both the North Pole and South Pole at the same time. Let me think about this.\n\nFirst, the Earth's geography. The North Pole is located at 90 degrees north latitude, and the South Pole is at 90 degrees south latitude. These are two distinct points on opposite ends of the Earth. \n\nSo, if someone is at the North Pole, they're in a specific location. To be at the South Pole, they'd have to travel all the way around the Earth. But since the person can't physically move through both poles simultaneously, it's impossible for them to be at both places at the same time.\n\nWait, but maybe there's a trick here? Like some kind of antipodal point or something. The North and South Poles are antipodal points, meaning they're directly opposite each other. But even then, being at one requires being away from the other. Unless the person is at a specific point that's both poles, but that's not possible.\n\nAlso, considering Earth's rotation and movement. The person can't be in two places at once. Even if they could teleport or something, which isn't feasible, there's no physical way to exist at both points simultaneously.\n\nSo the answer should be no, it's impossible for a person to be at both poles at the same time. They are on opposite ends of the Earth, so you can only be in one place at a time.\n</think>\n\nNo, a person cannot be at both the North Pole and South Pole at the same time. These are two distinct points on opposite ends of the Earth, separated by about 20,000 miles (32,000 km). You can only be in one location at a time.","role":"assistant"},"finish_reason":"stop","logprobs":null}],"usage":{"prompt_tokens":40,"completion_tokens":371,"total_tokens":411}}%
The Qwen3 4B model is really smart and it turns on the thinking mode!
RAG and Embeddings
Finally, if you are using this model to create agentic or RAG applications, you will likely need an API to compute vector embeddings for the user request text. That can be done by adding an embedding model to the LlamaEdge API server. Learn how this is done.
Gaia
Alternatively, the Gaia network software allows you to stand up the Qwen3 LLM, embedding model, and a vector knowledge base in a single command. Try it with Qwen-3!
Join the WasmEdge discord to share insights. Any questions about getting this model running? Please go to second-state/LlamaEdge to raise an issue or book a demo with us to enjoy your own LLMs across devices!