By arcosx, a senior software engineer in charge of Machine Learning platform at Baidu.

Introduction
UDF (User-defined function) is the type of function users can customize. In databases, UDF represents a mechanism for extending the capabilities of a database service by adding a function.
Wasm (WebAssembly) is a new format that is portable, small, fast loading, and compatible with the Web. In recent years, Wasm has not only been widely used on the front-end, but has also played an increasingly important role on the server-side. It provides performance close to native code on the server-side without sacrificing security.
In the Nebula Hackathon 2021 held by NebulaGraph, I combined UDF and wasm, implemented the first production-level user-defined function engine for it, and won the best project award. This article is a review aiming to share the vast potential of Wasm as an extension mechanism on the server-side to give the readers fresh perspectives.
Demand Analysis
User-defined functions’ extensive use cases
Right now, there are a lot of UDF implementations in mainstream databases or data process systems, such as
- Relational databases. Most relational databases, such as MySQL, Microsoft SQL Server, etc., support and have their own standards. In the relational database standard, there are two types of UDFs: Scalar Functions and Table Functions. Calling a scalar function returns only a single value, while a table-valued function returns a table with multiple rows and columns.
- Non-relational databases. Mainstream NoSQL, such as MongoDB and Cassandra, also support their unique UDFs. For example, MongoDB's UDF embeds Javascript functions, and Cassandra supports uploading jar packages as UDF. The embedding methods of these features are the same as these database implementation technologies are closely related.
- Big data computing engine. UDFs are supported in batch data computing engine Spark, and stream data computing engine Flink. These big data computing engines, to abstract computing models, become more user-friendly, design a set of development languages that conform to standard SQL semantics, which also includes UDF functions. For example, in the Flink engine, users can use UDFs to call frequently used or custom logic in query statements that are difficult to express in other ways.
- Cloud products. Many cloud providers are working in this direction. For example, Google BigQuery allows users to call code in JavaScript from SQL queries. Alibaba Cloud's MaxCompute can directly embed Java or Python code like UDF into SQL.
- Graph databases. The de facto graph database query statement standard openCypher has the definition of UDF, which is also supported by major graph databases. For example, Tiger Graph supports querying UDF in C++ language. Neo4j supports customized Java script UDF.
Wasm-based plugin sets a great example
As a front-end tech, Wasm has long been used extensively on the Web. For example, eBay provides a bar code scanning feature on the Web-based on Wasm. In addition, AutoCAD Web ported its native apps to the Web platform via Wasm.
The application of Wasm on the server-side is on the rise. Many applications are adopting Wasm technology on the server-side. For example, YoMo embeds WasmEdge into the real-time data stream, and then uses WasmEdge for AI inference of data, and also uses Wasm as an extension mechanism. In addition, WasmEdge can also be deployed on serverless platforms with no need for ops, with automatic scalability, and pay as you use.
There are some open-source projects that embed Wasm runtime into applications as an extension mechanism.
- The Envoy component in Istio adds a dynamic, extensible agent filter based on Wasm, which dramatically simplifies the further development and functionality enhancement of Envoy.
- MOSN uses Wasm to create a safe sandbox environment for users to run their plug-ins.
It must be mentioned that in the TiDB 2020 Hackathon, the’ or 0=0 or’ team implemented TiDB's user-defined functionx based on Wasm, which is the earliest case of using Wasm in a database, and it is also the source of inspiration for my work in the Nebula Hackathon 2021.
These examples show that Wasm has unlimited potential as an extension mechanism on the server-side.
Business Demands
Before discussing the specific implementation, let's look at the demands based on graph databases’ business attributes and models.
-
Complex logic bootstrapping reduces data interaction: Nebula graph database itself does not support some complex functions (such as JSON Parse), or specific logic processing (such as Join, Filter) that includes business systems. The UDF users can customize general logic to avoid repeated interaction between the business system and the database to reduce network communication and enhance performance.
-
Enhanced scalability for public cloud platforms: Like the cloud database products provided by many cloud providers, the Nebula graph database has a fully managed database-as-a-service (DBaaS) product called Nebula Graph Cloud14. As a public cloud platform, for unified management and operation and maintenance, standard binary software is usually deployed, and no customization is made for different users. Users can customize based on their business logic through UDF, but this logic should be restricted to a certain extent, which meets the demands without causing security problems.
For example, users cannot go beyond the database to the physical location/ server where the database is located, nor launch some network attacks through the database. What they can see are some internal indicators of their own database, and even embed their own business logic into the database.
-
In private DevOps use cases, it lowers the operation and maintenance requirements: As open-source software, when the Nebula graph database empowers many enterprise businesses to take off, there could be private deployment scenarios. Clients who use Nebula extensively also have their own customization needs. These demand Nebula's R&D costs (not all clients have Nebula's R&D capabilities) to maintain some code that deviates from the main branch, and some customers have their own private needs. The Nebula graph database must have a very flexible extension mechanism to save their own engineers for endless customization requirements. Under the cloud-native trend, the extension language for manufacturers and customers should be inclusive. The user's technology stack should not be restricted to the native language C++ of the Nebula graph database. The UDF engine allows multi-language code to be packaged into Wasm files and embedded in the Nebula graph database for execution. Thus in private deployment, the Nebula graph database only needs to ensure the stability of the core components, and the user's code is not merged back into Nebula. It should have the ability to extend on-demand.
Implementation Analysis
Painpoints and Expectations
Let's go back to the basics first. UDF is a plugin mechanism. So let's see the requirements for plugin mechanism when discussing UDF design.
- Security isolation requirements: Code risk control, program capability limitations at runtime, and call resource limitations. The UDF code caused potential risk to Nebula is solved by the sandbox. If there is any bug in the UDF written by the user, it will not affect Nebula's running.
- Elastic efficiency: Support basic capabilities such as dynamic distribution, installation/ uninstallation.
- Performance and size: Close to native code (C++) performance. Balance, features, and complexity are proportional to size.
- Write once, run anywhere. The operating platform is compatible with x86, ARM, and other architectures.
In addition, as a UDF based on a graph database, it should also have the following characteristics.
- Extensibility: You can use multiple languages (C/C++, Rust, Python, TypeScript) to write function logic, and you can also introduce other UDFs for combination and reuse.
- Reuse of existing infrastructure: The ability to support multiple languages, allowing modular programming, encapsulating function composition calls, and even directly reusing community UDF codes.
- Graph data combination: Support data structures unique to graph data (such as vertices, edges) as data structures available in functions
- Utilize cloud computing resources: Use modern cloud computing infrastructure to extend computing capabilities, connect to cloud function computing (AWS Lamda/Alibaba Cloud Function Compute), utilizing massive computing power.
- More complex functions: Beyond the traditional UDF simple data aggregation, and string splicing requirements. The introduction of complex computing logic, such as machine learning reasoning, ID-Mapping, etc.
Implementations
Although my final choice is to use Wasm as mentioned above, it is necessary to discuss the reason.
The figure below shows the implementation comparison of various UDF implementations. Many UDF implementations of data systems are listed above. The implementations are internal implemented DSL (such as Flink), loading of .so file (such as MySQL), and scripts embed, which all have certain limitations.
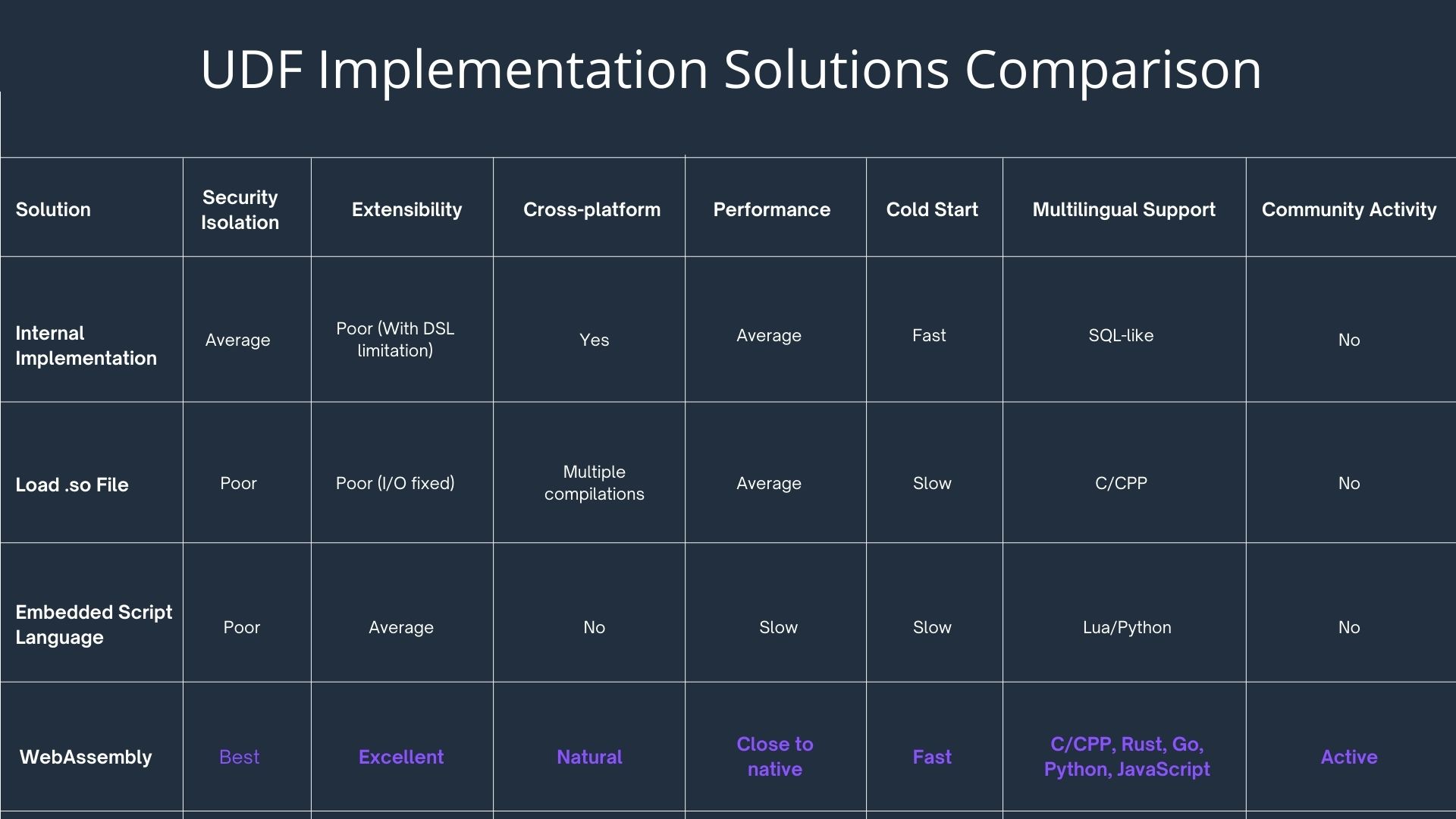
Next, we choose a specific Wasm runtime based on whether it has a complete C++ SDK, performance and size, community activity, whether it is easy to embed, and the documentation. Taking these into consideration, we chose WasmEdge and Wasmtime.
Specific Implementation
Architecture Graph
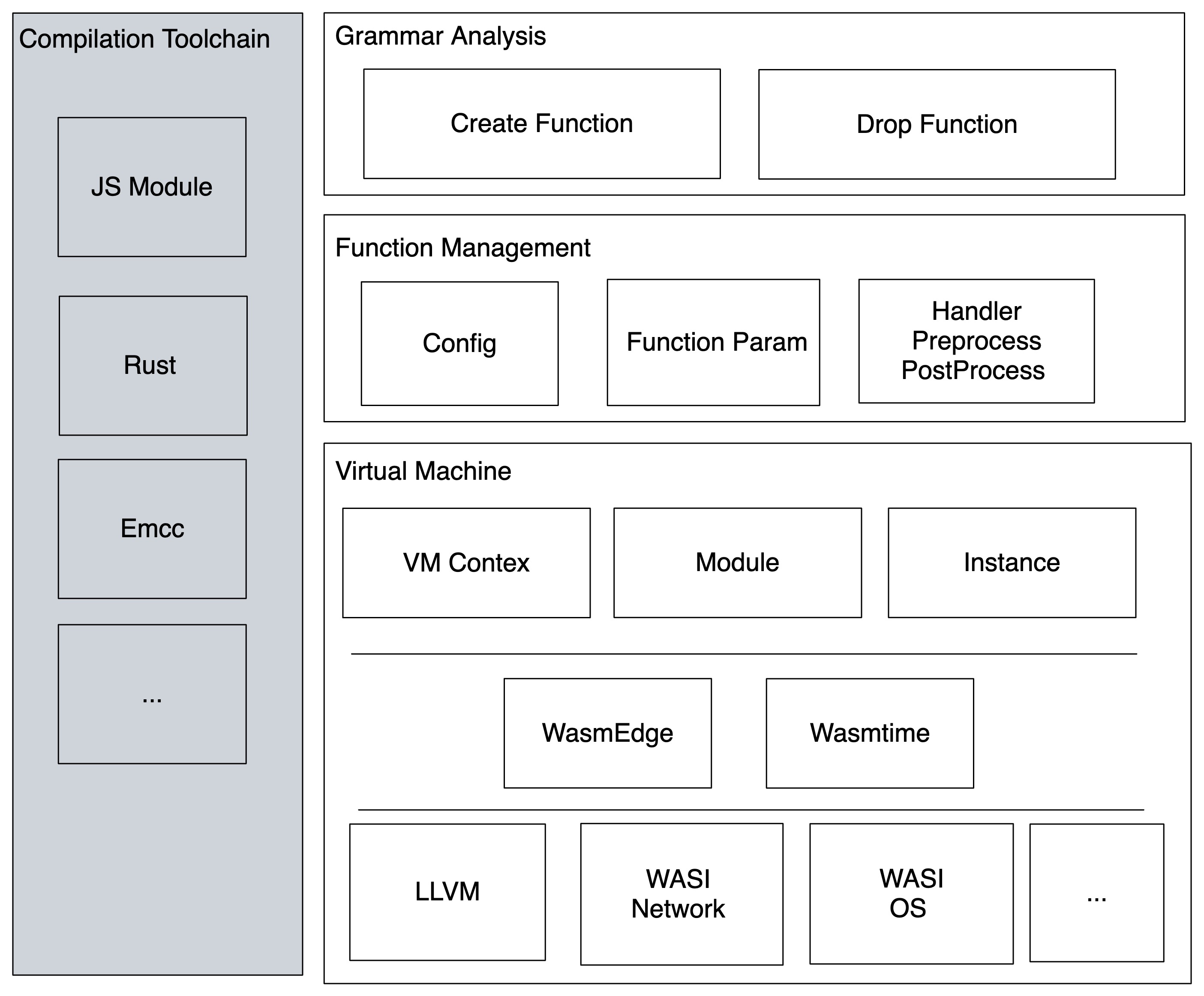
Single Modules Intro
Compilation Toolchain: It works to quickly convert existing code into Wasm. This module is relatively messy, and we use it to develop and debug the Wasm program for the Hackathon Demo.
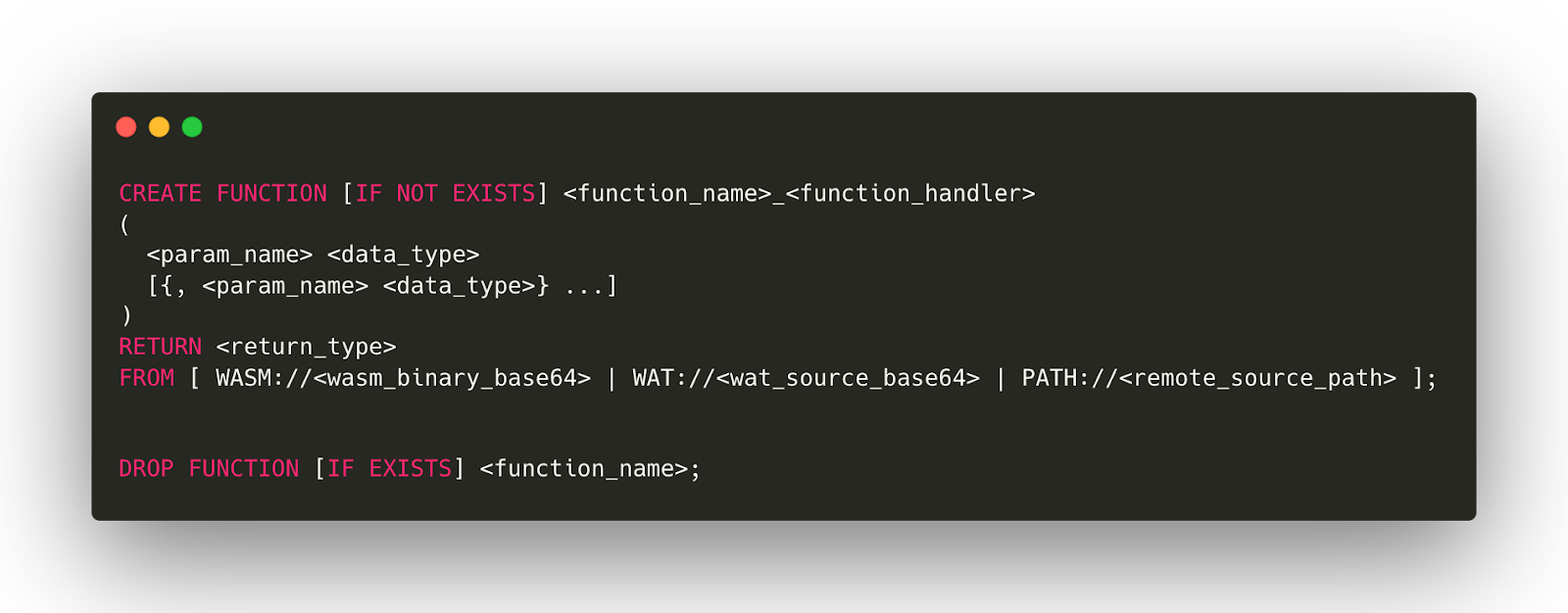
Parsing: Create functions based on Flex and Bison implementations, and delete SQL statements for functions. The implementation syntax is in the figure below. We consider the two mainstream formats of WebAssembly text format (wat) and Wasm binary files. And its loading methods have two types. The first one is wat base64 encoding, and Wasm binary file base64 encoding, which is convenient for direct input in the terminal, the program with the running size at the KB level can be directly imported. The second is the MB level Wasm Program binary files, which support importing by HTTP address and local file address.
Function Management: Responsible for unified management of Wasm virtual machines, providing dynamic update, loading, and unloading of functions. It can also be said to be the glue for Nebula's other systems and the Wasm extension components.
Runtime: Here we introduce the C++ SDK of two virtual machines, Wasmtime and WasmEdge. Calling SDK to compile wat code, compile and execute Wasm binary file, manage sandbox instances and WASI features, etc.
Work Flow
- When a function is created, the function name (name), the function parameters (params), the function return parameter (return type), and the function body (code or path) are obtained after parsing the syntax. First, load the data ontology through base64 decoding, HTTP download, and file reading operations. After loading, call the virtual machine API to compile it, and get the compiled Run context. Then, the function runs parameters, returns parameters, runs context, and concatenates into a function-running sandbox (Sandbox) that can be used directly by the virtual machine. The function name is Key, and the function running sandbox is Value stored in the memory hash table (Mem Table).
- When the function is called, use the function name as the key to find the function running sandbox in the memory hash table, perform parameter verification on the incoming parameters, and convert the data type in Nebula (C++ Data Struct) into parameters that the virtual machine can accept (Wasm Data Struct), request the virtual machine to execute the function to run the running context in the sandbox, get the running result, convert the returned parameter into the data type in Nebula, and return to the upper module.
- When a function is deleted, the function-running sandbox in the memory hash table is deleted.
Here I will not elaborate on the specific implementation in the module. Check out the GitHub code for details.
Demo
Below are the two demos for the Hackathon, which show the entire process and the extensibility of Wasm. Demos are based on WasmEdge Runtime. The code is open sourced.
String concatenation program based on WasmEdge
I create a demo showing a very simple string concatenation. This function is not native to the Nebula graph database.
Pass in a string world and return the concatenated string hello world. Note that this extension attempts to pass strings to the Wasm virtual machine, which are not supported by the WebAssembly specification. Here we use the wasm_bindgen tool to compile the Rust program into a Wasm program by mapping the string to the memory address of the virtual machine. You can find the method in the WasmEdge Book or the open source code of the demo.
IM chatbot based on WasmEdge
I also created a demo showing how to send messages from the database to an instant messaging app Lark's chatbot. First, we get the API of a Feishu app chatbot. This API is a HTTP Post request. Next, use WasmEdge's WASI socket to embed the UDF with network request function into the database and execute the function. Finally, you can see that the program requests Feishu to export the content successfully.
Why this demo? The traditional UDF of the database mainly works to customize data aggregation and the storage process, which are essential database business attributes and capabilities. It is more practical to show a Wasm-based plugin mechanism that completely surpasses the traditional UDF of the database in its comprehensive functionalities. Suppose the business system can load Wasm extensions in multiple systems as a Hook (hook) mechanism. In that case, users can add their own Wasm extensions without greatly changing their original business system and achieve various customized functionalities. We may use this to improve the observability of the program. For example, when the database receives a slow query statement, trigger a Hook and send the slow query result to the database administrator via internal IM. I believe there is great potential here.
The Lackings and Upcomings
Lackings
Reflecting on the Hackathon, I feel that many can be improved. The following discussion is my expectation of what a complete Wasm extension mechanism should have.
More dynamic functions and runtime management and operation mechanisms are not achieved.
- Since the UDF is made in the graph database, I prioritized the addition, deletion, and modification of functions in the form of SQL. In my original idea, the overall Wasm UDF function should have a dynamic configuration, which can limit the number of sandbox instances, the virtual machines used, the permissions of the virtual machines (such as the network provided by WASI, IO permissions), etc.
- In terms of the working mechanism, at the beginning of the design, I also considered having specific functions executed on the cloud (such as AWS Lamda), and having results returned to the database. Upon researching, WasmEdge virtual machinehas networking feature. However, there is a lot to think about when it comes to specific implementations, such as coordinating the interaction between this “cloud UDF” and the local UDF, planning the function running callback, etc. Therefore, I didn't achieve.
Calling Nebula graph database API from inside the Wasm function is not achieved.
- My work is limited to calling Wasm functions from the Nebula graph database, which is the most direct way to use Wasm, but Wasm itself can call the Host Function via the API,. I also found a similar method in the Doc of the C SDK of WasmEdge.
- However, subject to the security mechanism of Wasm, any access to external resources must be achieved indirectly by importing modules. Therefore, it is necessary to add a layer of data conversion to the input and output parameters of the internal API of the Nebula graph database and pass it into Wasm, which requires aligning and abstracting the mapping of external data structures in the Wasm program.
- These tasks are challenging, so it is difficult to implement Wasm UDFs now. However, we would be able to apply this beyond UDF to embed our Wasm sandbox on multiple applications to achieve the Hook mechanism if these challenges were tackled.
Performance evaluation
- The performance of Wasm programs when processing large-scale data is not evaluated.
Lack of diverse and complex functionalities
- An existing application's migration and adaptation require quite some work. For example, I tried to embed jq (a JSON string processor written in C) into the graph database, so that the graph database can directly support the processing of JSON-type strings. Still, in the process of trying, it is found that the compilation is cumbersome, and then import into the VM does not run smoothly.
- After examining the WasmEdge's support for using Tensorflow for machine learning inference, I envisage loading a structured data model inside Wasm, reading the data stored in the Nebula graph database, running a simple clustering or regression, and doing some Inference services related to upper-layer graph data, or compile a complete graph algorithm into Wasm. These features can utilize Wasm as an extension mechanism to outperform traditional UDFs.
What's next
Wasm works as a reliable sandbox environment in more extending use cases. The extending plugin code will not cause safety risks for the the applications running above. Although V8, JVM, Lua, and other virtual machines also have the same security capabilities, their performance and size, multi-language support, and scalability are not as good as Wasm.
Although this article mainly discusses the implementation of the graph database UDF, the process applies to any projects that use Wasm as extensions. WebAssembly VM such as WasmEdge and Wasmtime have prepped many low-level executions, saving me a lot of time. Part of the work focuses on the interaction between the host and the Wasm extension, function registration deletion, function call, data transmission, etc. I believe it is effortless to integrate Wasm quickly and extend with Wasm.
The cloud data service by the Nebula graph database in this article or software service represented is a SaaS platform. If SaaS platforms allow user-defined code like UDF to be directly uploaded to the platform, developers do not need to maintain the middle layer that handles callbacks and thus reduce data links, nor manage infrastructure. Also, they can reuse the existing APIs of the SaaS platform, ensuring high security, outstanding performance, and higher scalability.
Join us in the WebAssembly revolution!
👉 Discord server: WasmEdge Discord server
👉 Mailing list: Send an email to WasmEdge@googlegroups.com
👉 Twitter: @realwasmedge
👉 Be a contributor: checkout our wish list to start contributing!